| 深度学习第三课第一周笔记–机器学习策略(1) |
1. 正交化
表示在机器学习模型建立的整个流程中,我们需要根据不同部分反映的问题,去做相应的调整,从而更加容易地判断出是在哪一个部分出现了问题,并做相应的解决措施。
正交化或正交性是一种系统设计属性,其确保修改算法的指令或部分不会对系统的其他部分产生或传播副作用。 相互独立地验证使得算法变得更简单,减少了测试和开发的时间。
当在监督学习模型中,以下的4个假设需要真实且是相互正交的:
- 系统在训练机上表现的好,否则使用 更大的神经网络、更好的优化算法
- 系统在开发集上表现的好,否则使用 正则化、更大的训练集
- 系统在测试集上表现的好,否则使用 更大的开发集
- 系统在真实的系统中表现的好,否则 修改开发测试集、代价函数
2. 单一数字评估指标
在训练机器学习模型的时候,无论是调整超参数,还是尝试更好的优化算法,为问题设置一个单一数字评估指标,可以更好更快的评估模型。
F1 Score
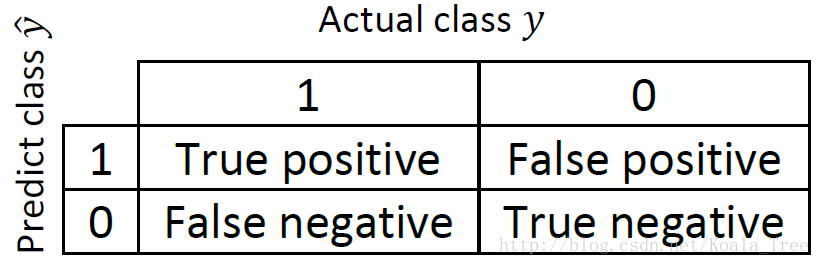
- Precision(查准率):
\[Precision = \dfrac{True\ positive}{Number\ of\ predicted\ positive} \times 100\%= \dfrac{True\ positive}{True\ positive + False\ positive}\]
假设在是否为猫的分类问题中,查准率代表:所有模型预测为猫的图片中,确实为猫的概率。
- Recall(查全率):
\[Recall = \dfrac{True\ positive}{Number\ of\ actually\ positive} \times 100\%= \dfrac{True\ positive}{True\ positive + False\ negative}\]
假设在是否为猫的分类问题中,查全率代表:真实为猫的图片中,预测正确的概率。
- F1 Score:
\[F1Socre = \dfrac {2} {\dfrac{1}{p}+\dfrac{1}{r}}\]
3. 满足和优化指标
有时对于某一问题,对模型的效果有一定的要求,如要求模型准确率尽可能的高,运行时间在100 ms以内。这里以Accuracy为优化指标,以Running time为满足指标,我们可以从中选出B是满足条件的最好的分类器。
一般的,如果要考虑N个指标,则选择一个指标为优化指标,其他N-1个指标都是满足指标
4. 改变开发、测试集和评估指标
在针对某一问题我们设置开发集和评估指标后,这就像把目标定在某个位置,后面的过程就聚焦在该位置上。但有时候在这个项目的过程中,可能会发现目标的位置设置错了,所以要移动改变我们的目标。
Example1
假设有两个猫的图片的分类器:
- 评估指标:分类错误率
- 算法A:3%错误率
- 算法B:5%错误率
这样来看,算法A的表现更好。但是在实际的测试中,算法A可能因为某些原因,将很多色情图片分类成了猫。所以当我们在线上部署的时候,算法A会给爱猫人士推送更多更准确的猫的图片(因为其误差率只有3%),但同时也会给用户推送一些色情图片,这是不能忍受的。所以,虽然算法A的错误率很低,但是它却不是一个好的算法。
这个时候我们就需要改变开发集、测试集或者评估指标。
假设开始我们的评估指标如下:
\[Error = \dfrac{1}{m_{dev}}\sum\limits_{i=1}^{m_{dev}}I\{y^{(i)}_{pred}\neq y^{(i)}\}\]
该评估指标对色情图片和非色情图片一视同仁,但是我们希望,分类器不会错误将色情图片标记为猫。
修改的方法,在其中加入权重\(w^{(i)}\):
\[Error = \dfrac{1}{\sum w^{(i)}}\sum\limits_{i=1}^{m_{dev}} w^{(i)}I\{y^{(i)}_{pred}\neq y^{(i)}\}\]
其中:
\[w^{(i)}=\left\{ \begin{array}{l}
1\qquad \qquad \qquad 如果x^{(i)}不是色情图片\
10或100\qquad \qquad如果x^{(i)}是色情图片
\end{array} \right.\]
这样通过设置权重,当算法将色情图片分类为猫时,误差项会快速变大。 总结来说就是:如果评估指标无法正确评估算法的排名,则需要重新定义一个新的评估指标。
Example2
同样针对 example1 中的两个不同的猫图片的分类器A和B。
但实际情况是对,我们一直使用的是网上下载的高质量的图片进行训练;而当部署到手机上时,由于图片的清晰度及拍照水平的原因,当实际测试算法时,会发现算法B的表现其实更好。
如果在训练开发测试的过程中得到的模型效果比较好,但是在实际应用中自己所真正关心的问题效果却不好的时候,就需要改变开发、测试集或者评估指标。
Guideline:
- 定义正确的评估指标来更好的给分类器的好坏进行排序;
- 优化评估指标。
5. 与人类表现做比较
理解人类表现
如医学图像分类问题上,假设有下面几种分类的水平:
- 普通人:3% error
- 普通医生:1% error
- 专家:0.7% error
- 专家团队:0.5% error
在减小误诊率的背景下,人类水平误差在这种情形下应定义为:0.5% error;
如果在为了部署系统或者做研究分析的背景下,也许超过一名普通医生即可,即人类水平误差在这种情形下应定义为:1% error;
总结:
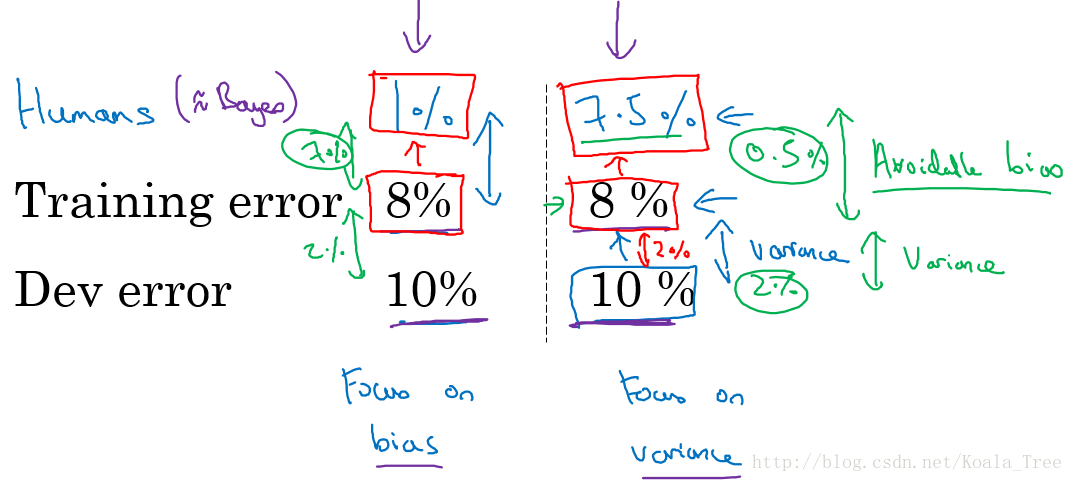
对人类水平误差有一个大概的估计,可以让我们去估计贝叶斯误差,这样可以让我们更快的做出决定:减少偏差还是减少方差。
而这个决策技巧通常都很有效果,直到系统的性能开始超越人类,那么我们对贝叶斯误差的估计就不再准确了,再从减少偏差和减少方差方面提升系统性能就会比较困难了。
6. 改善模型的表现
基本假设:
- 模型在训练集上有很好的表现
- 模型推广到开发和测试集也有很好的表现
减少可避免偏差:
- 训练更大的模型
- 训练更长时间、训练更好的优化算法(Momentum、RMSprop、Adam)
- 寻找更好的网络架构(RNN、CNN)、寻找更好的超参数
减少方差:
- 收集更多的数据
- 正则化(L2、dropout、数据增强)
- 寻找更好的网络架构(RNN、CNN)、寻找更好的超参数