| 深度学习第四课第三周笔记–目标检测 |
1. 目标检测
滑动窗口的卷积实现
在我们实现了以卷积层替代全部的全连接层以后,在该基础上进行滑动窗口在卷积层上的操作。下面以一个小的图片为例:
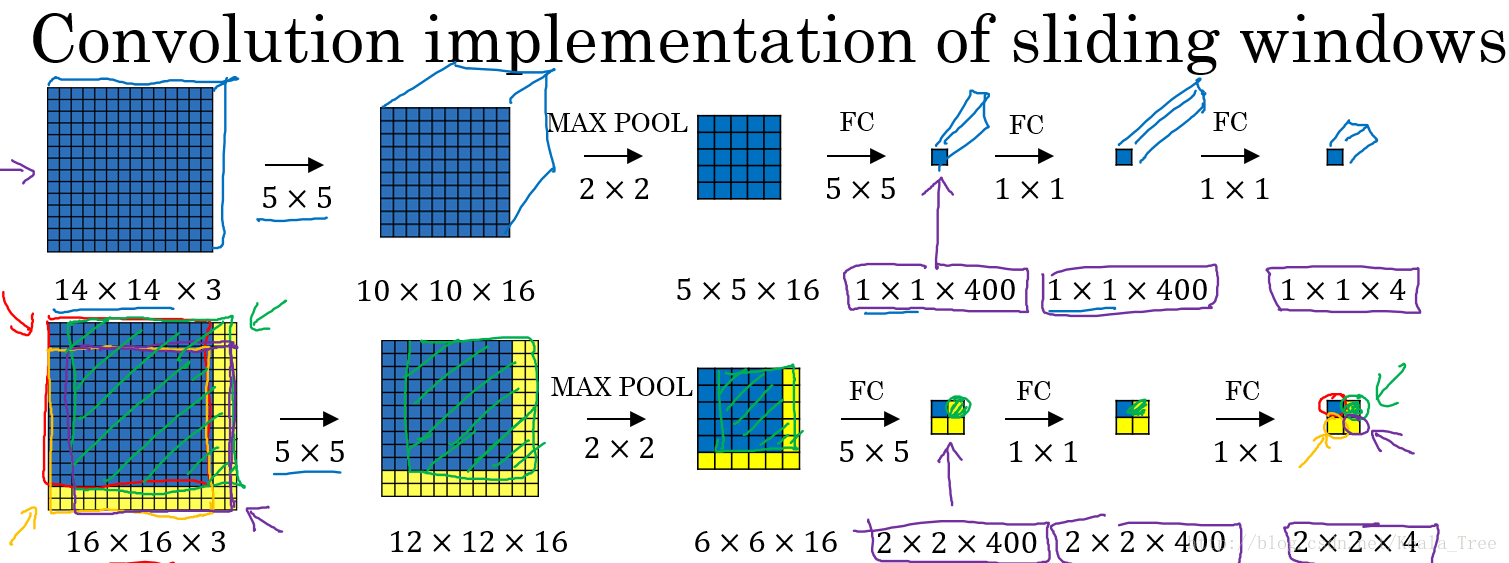
我们以上面训练好的模型,输入一个16×16×3大小的整幅图片,图中蓝色部分代表滑动窗口的大小。我们以2为大小的步幅滑动窗口,分别与卷积核进行卷积运算,最后得到4幅10×10×16大小的特征图,然而因为在滑动窗口的操作时,输入部分有大量的重叠,也就是有很多重复的运算,导致在下一层中的特征图值也存在大量的重叠,所以最后得到的第二层激活值(特征图)构成一副12×12×16大小的特征图。对于后面的池化层和全连接层也是同样的过程。
那么由此可知,滑动窗口在整幅图片上进行滑动卷积的操作过程,就等同于在该图片上直接进行卷积运算的过程。所以卷积层实现滑动窗口的这个过程,我们不需要把输入图片分割成四个子集分别执行前向传播,而是把他们作为一张图片输入到卷积神经网络中进行计算,其中的重叠部分(公共区域)可以共享大量的计算。
2. Bounding Box预测
YOLO
YOLO算法可以使得滑动窗口算法寻找到更加精准的边界框。
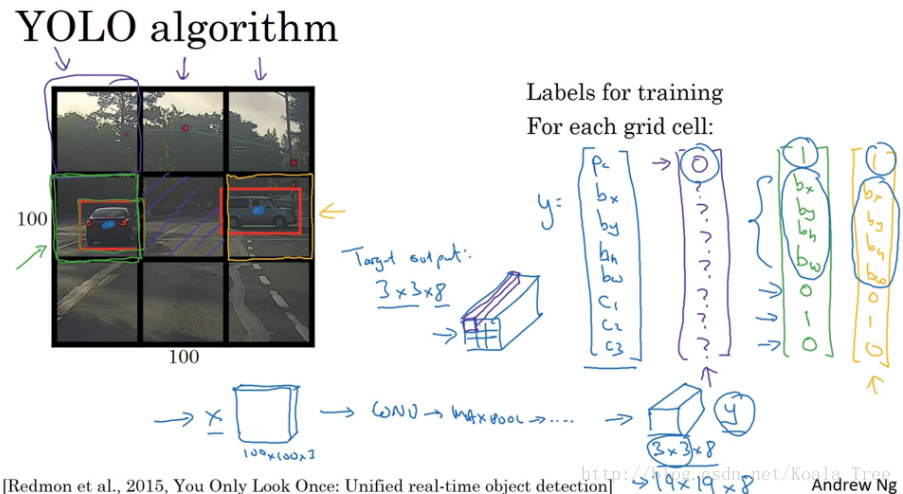
- 在整幅图片上加上较为精细的网格,将图片分割成n×n个小的图片
- 采用图像分类和定位算法,分别应用在图像的n×n个格子中
- 定义训练标签:(对于每个网格,定义如前面的向量yi)
\(y_{i} = \left[ \begin{array}{l}
P_{c}\
b_{x}\
b_{y}\
b_{h}\
b_{w}\
c_{1}\
c_{2}\
c_{3}
\end{array} \right]\) 对于不同的网格 i 有不同的标签向量yi。 - 将n×n个格子标签合并在一起,最终的目标输出Y的大小为:n×n×8(这里8是因为例子中的目标值有8个)。
通过这样的训练集训练得到目标探测的卷积网络模型。我们利用训练好的模型,将与模型输入相同大小的图片输入到训练好的网络中,得到大小为n×n×8的预测输出。通过观察n×n不同位置的输出值,我们就能知道这些位置中是否存在目标物体,然后也能由存在物体的输出向量得到目标物体的更加精准的边界框。
- 对于每个网格,以左上角为(0,0),以右下角为(1,1)
- 宽高\(b_h、b_w\)表示比例值,存在>1的情况
3. 交并比(Intersection-over-Union)
交并比函数用来评价目标检测算法是否运作良好。

对于理想的边界框和目标探测算法预测得到的边界框,交并比函数计算两个边界框交集和并集之比。
一般在目标检测任务中,约定如果 \(IoU⩾0.5\) ,那么就说明检测正确。当然标准越大,则对目标检测算法越严格。得到的IoU值越大越好。
4. 非最大值抑制(non-max suppresion,NMS)
对于我们前面提到的目标检测算法,可能会对同一个对象做出多次的检测,非最大值抑制可以确保我们的算法对每个对象只检测一次。
多网络检测同一物体
对于汽车目标检测的例子中,我们将图片分成很多精细的格子。最终预测输出的结果中,可能会有相邻的多个格子里均检测出都具有同一个对象。
NMS算法思想

- 在对n×n个网格进行目标检测算法后,每个网格输出的\(P_c\)为一个0~1的值,表示有车的概率大小。其中会有多个网格内存在高概率
- 得到对同一个对象的多次检测,也就是在一个对象上有多个具有重叠的不同的边界框
- 非最大值抑制对多种检测结果进行清理:选取最大\(P_c\)的边界框,对所有其他与该边界框具有高交并比或高重叠的边界框进行抑制
- 逐一审视剩下的边界框,寻找最高的\(P_c\)值边界框,重复上面的步骤
- 非最大值抑制,也就是说抑制那些不是最大值,却比较接近最大值的边界框
5. Anchor Box
通过上面的各种方法,目前我们的目标检测算法在每个格子上只能检测出一个对象。使用Anchor box 可以同时检测出多个对象。
重叠目标
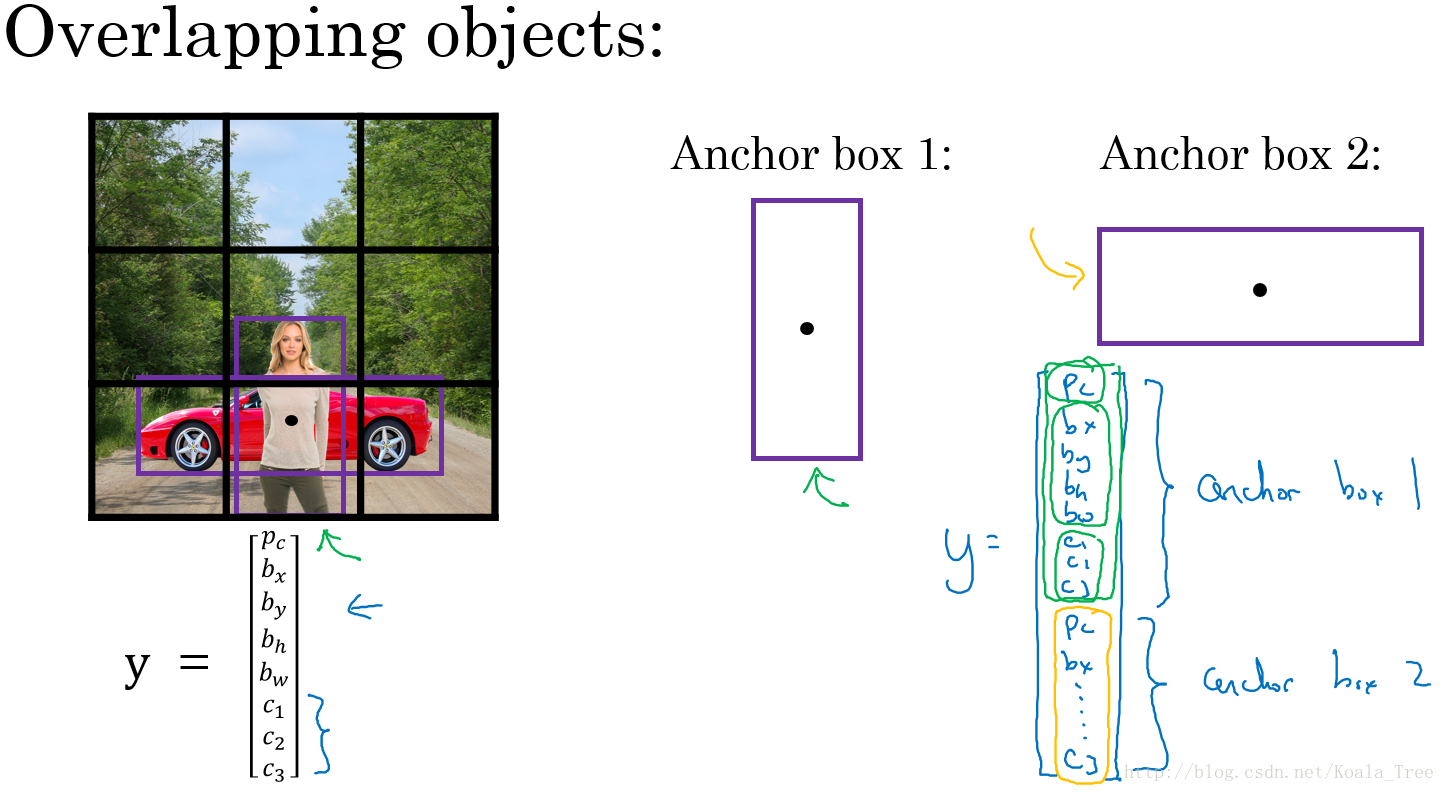
对于重叠的目标,这些目标的中点有可能会落在同一个网格中,对于我们之前定义的输出:\(y_{i} = \left[ \begin{array}{l}
P_{c}\
b_{x}\
b_{y}\
b_{h}\
b_{w}\
c_{1}\
c_{2}\
c_{3}
\end{array} \right]\),只能得到一个目标的输出。
而Anchor box 则是预先定义多个不同形状的Anchor box,我们需要把预测目标对应地和各个Anchor box 关联起来,所以我们重新定义目标向量:
\(y_{i} = \left[
P_{c}\
b_{x}\
b_{y}\
b_{h}\
b_{w}\
c_{1}\
c_{2}\
c_{3}\
P_{c}\
b_{x}\
b_{y}\
b_{h}\
b_{w}\
c_{1}\
c_{2}\
c_{3}\cdots\right]\)
用这样的多目标向量分别对应不同的Anchor box,从而检测出多个重叠的目标。
问题
- 如果我们使用了两个Anchor box,但是同一个格子中却有三个对象的情况,此时只能用一些额外的手段来处理
- 同一个格子中存在两个对象,但它们的Anchor box 形状相同,此时也需要引入一些专门处理该情况的手段
Anchor Box选择
- 一般人工指定Anchor box 的形状,选择5~10个以覆盖到多种不同的形状,可以涵盖我们想要检测的对象的形状
- 高级方法:K-means 算法:将不同对象形状进行聚类,用聚类后的结果来选择一组最具代表性的Anchor box,以此来代表我们想要检测对象的形状
6. YOLO算法实例
假设我们要在图片中检测三种目标:行人、汽车和摩托车,同时使用两种不同的Anchor box。
-
训练集
- 输入X:同样大小的完整图片
- 目标Y:使用3×3网格划分,输出大小3×3×2×8,或者3×3×16
- 对不同格子中的小图,定义目标输出向量Y
- 模型预测
- 运行非最大值抑制
-
假设使用了2个Anchor box,那么对于每一个网格,我们都会得到预测输出的2个bounding boxes,其中一个\(P_c\)比较高

-
抛弃概率\(P_c\)值低的预测bounding boxes

-
对每个对象(如行人、汽车、摩托车)分别使用NMS算法得到最终的预测边界框

-
7. 候选区域(region proposals)
R-CNN
R-CNN(Regions with convolutional networks),会在我们的图片中选出一些目标的候选区域,从而避免了传统滑动窗口在大量无对象区域的无用运算。
所以在使用了R-CNN后,我们不会再针对每个滑动窗口运算检测算法,而是只选择一些候选区域的窗口,在少数的窗口上运行卷积网络。
具体实现:运用图像分割算法,将图片分割成许多不同颜色的色块,然后在这些色块上放置窗口,将窗口中的内容输入网络,从而减小需要处理的窗口数量。

更快的算法
- R-CNN:给出候选区域,对每个候选区域进行分类识别,输出对象 标签 和 bounding box,从而在确实存在对象的区域得到更精确的边界框,但速度慢
- Fast R-CNN:给出候选区域,使用滑动窗口的卷积实现去分类所有的候选区域,但得到候选区的聚类步骤仍然非常慢
- Faster R-CNN:使用卷积网络给出候选区域